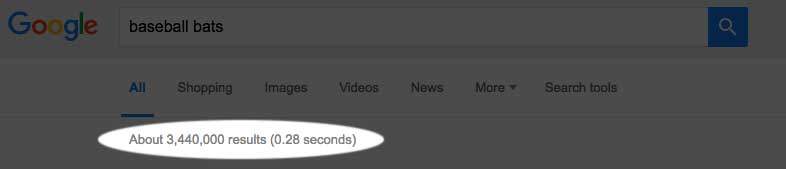
You’re doing some online research for your kid’s little league team. You open a browser window to search for “baseball bats.” You hit “Enter” and WHAM! … three-and-a-half million results in about a quarter of a second. Stop to think about that. Google had to:
- accept your query
- parse your query
- figure out the word order
- look up the information in its database
- personalize your results by taking into account everything it knows about you (which is A LOT)
- rank the results
- send the results to your browser
…and it did all this, returning 3.44 million results in 0.28 seconds.
How Does Google Return Results So Damn Fast?!?
To be perfectly honest, I think only a small handful of very important people at Google know the full extent of exactly how it’s done–and it’s possible that no one person fully knows or understands every detail of it. The rest of us have to make educated guesses based on tidbits of information we learn here and there.
The first thing we have to understand is that Google does not search the Internet when you submit a query for baseball bats. Google searches its index of the internet. This might seem trivial but it’s an important distinction because it makes the search infinitely faster.
Think of it this way… When you are looking in a cookbook to try and figure out what the hell to do with this two-week-old rutabaga you got from your last visit to Old Aunt Harriet, you would not flip through every page of the book looking for rutabaga recipe–you would flip to the index in the back, look under “R” for rutabaga, and the look at the specific pages listed in the index.
That’s exactly what Google does except its index holds pointers to the entire information of the world and is infinitely larger than the index in your average cookbook. Google admits that its index is over 100 million gigabytes (100,000,000,000,000,000,000 bytes)…which means the index is probably many times that size.
Apart from the basic “search the index not the web” concept, this is what the hive mind of the internet has surmised is the most likely set of technologies that help Google achieve these speed.
Multiple Datacenters with a Worldwide Load Balancing Network
Like many components of its internal workings, Google is famously tight-lipped about the number and location of datacenters they operate. Suffice to say that it’s a lot and they’re all over the world. This article from 2012 indicates that there are 21 datacenters in the United States alone with another 22 datacenters in other countries. They have probably built more in the last four years so I feel safe assuming that 43 global datacenters is probably a significant underestimate.
Regardless, when you submit a query for “baseball bats” on the Google homepage, a smart piece of network equipment will direct your search to the datacenter nearest your physical location. If that datacenter happens to be overwhelmed or out of operation for some reason, you will be redirected to the next closest datacenter, and so forth on down the line.
Distance matters in this case because even though your search travels through the network at the speed of light, a longer distance still means a longer time.
Hundreds of Computers in Each Datacenter Using Distributed Lookups
Each of Google’s several dozen datacenters houses many hundreds of individual computers. These computers are all networked so they can exchange data and work together. When your query gets to the datacenter, it is assigned to one master server that breaks the job apart and assigns lookup tasks to a number of worker servers. These worker servers look through their portion of Google’s web index to return the best results possible for your query. The results get returned to the master server which organizes and sorts them and then sends the results back to your browser.
When you perform a search, you might be using the capabilities of a dozen or even two dozen servers…and those servers have the capacity to handle multiple lookups like this simultaneously…and there are hundreds of servers in the datacenter…and a few dozen datacenters around the world. All the combined and Google has some serious lookup horsepower at its disposal.
Custom File System and Custom Software
The majority of the critical software running on these servers in the datacenters is custom–written by Google engineers and exclusively for Google’s use. This software ranges from the filesystem itself–called GFS or Collosus–to the spiders that crawl the web, to the database management systems, to specialized programming languages for creation and control of these new software packages.
There is way too much to try and cover in this article but you can read more about Google’s Datacenter Software here and their newest Cloud Software here. Every ounce of this software is designed to increase speed and decrease the amount of time it takes to return your search results.
More Speculative Methods
While I couldn’t find any specific information about these topics online, I would not be surprised if some or all of them were used to speed up the search results process.
- Caching — I am sure that there are often cases when many people online are searching for the same information or very similar information around the same time. For example, recently the 2016 Presidential Debates were live-streamed online. There were probably thousands of people searching Google for “live stream presidential debate” or some variation thereof. I would bet that Google cached the results of that query in a top-level server so that it’s machines would not even have to look up the information each time it’s searched for.
- Index Stored in RAM — Hard drives–even solid state hard drives–are slow compared to RAM. For the highest possible speeds, the index in the worker servers would probably be stored in RAM instead of on disk.
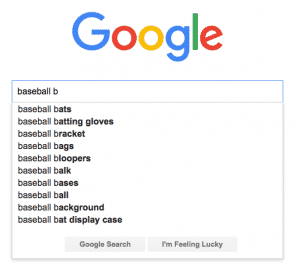 Pre-fetching Results — When we type “baseball bats” into a Google search bar, the search engine automatically populates it’s best guess for what we want as we type. While this is helpful to us as users to not have to completely type out our thought, it’s even more helpful to Google who can look-up the first five or ten or dozen of those pre-fetched search terms and have them nearly instantly available to the user once the “Enter” key is depressed.
Pre-fetching Results — When we type “baseball bats” into a Google search bar, the search engine automatically populates it’s best guess for what we want as we type. While this is helpful to us as users to not have to completely type out our thought, it’s even more helpful to Google who can look-up the first five or ten or dozen of those pre-fetched search terms and have them nearly instantly available to the user once the “Enter” key is depressed.
One other thing to remember is that Google is under no obligation to provide the most accurate, most consistent, or the most up-to-date results. If your search for baseball bats returns a listing for a company that went out of business five years ago, you will shrug your shoulders, think “That’s odd,” click a different link or do a different search, and forget all about it within the next ten seconds.
Because we typically find an acceptable set of results within an acceptable time frame when performing searches, in a certain way, we as users place a blind trust in a web search process. We just accept at face value that the search results we see are the very best search results possible–even if there are more accurate results available. So as long as the results we receive are close enough and we return to the search engine for more searches (and more ad views), that’s good enough for Google.
Leave a Reply